Deconstructing the Power of MapReduce: A Comprehensive Guide to its Execution
Related Articles: Deconstructing the Power of MapReduce: A Comprehensive Guide to its Execution
Introduction
With great pleasure, we will explore the intriguing topic related to Deconstructing the Power of MapReduce: A Comprehensive Guide to its Execution. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
- 1 Related Articles: Deconstructing the Power of MapReduce: A Comprehensive Guide to its Execution
- 2 Introduction
- 3 Deconstructing the Power of MapReduce: A Comprehensive Guide to its Execution
- 3.1 The Fundamental Components
- 3.2 The Orchestration: A Symphony of Tasks
- 3.3 The Power of Parallelism: Scaling for Big Data
- 3.4 Use Cases: A Wide Spectrum of Applications
- 3.5 Understanding the Benefits: A Foundation for Success
- 3.6 FAQs: Addressing Common Questions
- 3.7 Tips for Successful MapReduce Job Runs
- 3.8 Conclusion: A Legacy of Innovation and Impact
- 4 Closure
Deconstructing the Power of MapReduce: A Comprehensive Guide to its Execution

MapReduce, a programming model and software framework, revolutionized data processing by enabling the parallel execution of complex tasks across distributed systems. This approach, popularized by Google and now implemented in frameworks like Hadoop and Spark, has become a cornerstone of big data analysis. Understanding the anatomy of a MapReduce job run is crucial for appreciating its power and efficiency.
The Fundamental Components
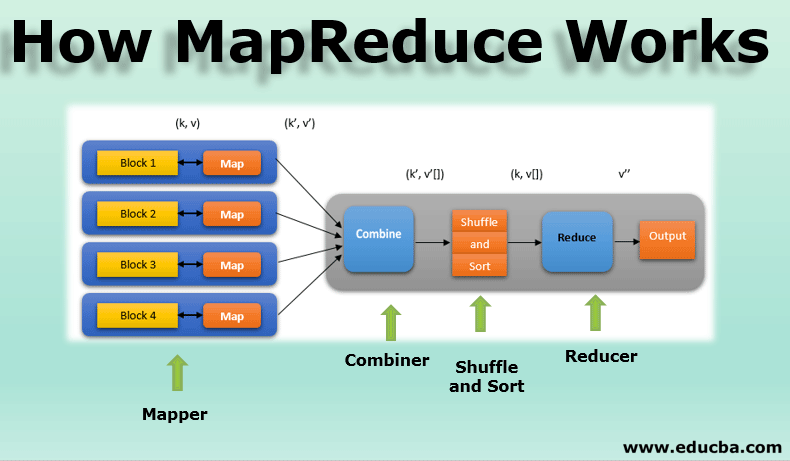
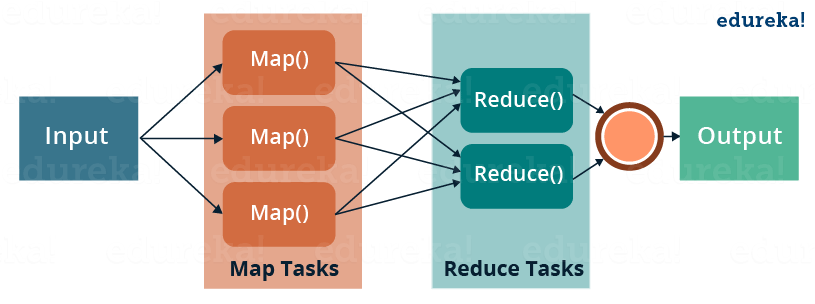
A MapReduce job run comprises two key phases: Map and Reduce, each with specific functions and responsibilities. These phases are executed across multiple nodes in a distributed environment, harnessing the collective processing power of the cluster.
1. The Map Phase:
- Input: The Map phase begins with the input data, typically residing in a distributed file system. This data is divided into smaller chunks, each assigned to a specific Map task.
- Transformation: Each Map task applies a user-defined function, the "map function," to its assigned data chunk. This function transforms the input data into key-value pairs. The key represents a category or grouping, while the value holds the associated data.
- Intermediate Output: The map tasks produce intermediate key-value pairs, which are then sorted and grouped based on their keys. This sorted intermediate output is sent to the Reduce phase.
2. The Reduce Phase:
- Input: The Reduce phase receives the sorted intermediate key-value pairs from the Map phase. These pairs are further grouped by their keys, forming a collection of values for each unique key.
- Aggregation: Each Reduce task applies a user-defined "reduce function" to the collection of values associated with a specific key. This function aggregates the values, performing operations like summing, averaging, or counting.
- Final Output: The Reduce tasks produce the final output of the MapReduce job. This output represents the aggregated results of the data processing, often written to a distributed file system for further analysis.
The Orchestration: A Symphony of Tasks
The execution of a MapReduce job involves a complex interplay of tasks and processes, orchestrated by a master node:
- Job Tracker: The Job Tracker is responsible for managing the overall execution of the MapReduce job. It divides the input data into chunks, assigns tasks to worker nodes, monitors task progress, and handles failures.
- Task Trackers: Task Trackers reside on each worker node. They execute the Map and Reduce tasks assigned to them, handling data processing and communication with the Job Tracker.
- Data Locality: MapReduce prioritizes data locality, aiming to execute Map tasks on nodes where the input data resides, minimizing data transfer and improving efficiency.
- Fault Tolerance: MapReduce is designed for robustness. If a worker node fails, the Job Tracker re-assigns its tasks to other available nodes, ensuring job completion.
The Power of Parallelism: Scaling for Big Data
The true power of MapReduce lies in its parallel execution capabilities. By dividing the workload into multiple tasks executed concurrently across a distributed cluster, MapReduce can handle massive datasets that would be impossible to process on a single machine. This parallel processing not only accelerates computation but also provides a scalable solution for ever-growing data volumes.
Use Cases: A Wide Spectrum of Applications
MapReduce’s versatility extends to various data processing tasks, including:
- Data Analysis: Analyzing large datasets to identify patterns, trends, and insights.
- Data Transformation: Converting data from one format to another, cleaning and preparing data for analysis.
- Machine Learning: Training machine learning models on large datasets, enabling efficient model development and deployment.
- Search Indexing: Creating and maintaining search indexes for large datasets, enabling fast and efficient information retrieval.
- Social Media Analysis: Analyzing social media data to understand user behavior, sentiment, and trends.
Understanding the Benefits: A Foundation for Success
The anatomy of a MapReduce job run reveals its inherent benefits:
- Scalability: MapReduce can process massive datasets by distributing the workload across a cluster of machines.
- Fault Tolerance: The framework handles node failures seamlessly, ensuring job completion even in the face of hardware issues.
- Simplicity: MapReduce provides a high-level abstraction, allowing developers to focus on the core logic of their data processing tasks.
- Efficiency: Data locality and parallel execution optimize resource utilization and accelerate processing.
- Cost-Effectiveness: MapReduce leverages commodity hardware, making it a cost-effective solution for big data processing.
FAQs: Addressing Common Questions
1. What are the limitations of MapReduce?
While powerful, MapReduce has limitations:
- Limited Flexibility: The MapReduce model can be restrictive for complex data processing scenarios that require more intricate data flow.
- Data Shuffle Overhead: The shuffling of intermediate data between Map and Reduce phases can introduce overhead, especially for large datasets.
- Real-Time Processing: MapReduce is not well-suited for real-time data processing applications, as its batch-oriented approach introduces latency.
2. What are the alternatives to MapReduce?
Several alternatives have emerged to address the limitations of MapReduce, including:
- Spark: A faster and more flexible framework that supports both batch and real-time processing.
- Flink: A streaming data processing framework designed for real-time applications.
- Hadoop YARN: A resource management framework that can support various processing engines, including MapReduce and Spark.
3. How do I choose the right framework for my needs?
The choice of framework depends on the specific requirements of the data processing task:
- For batch processing of large datasets: MapReduce or Spark are suitable options.
- For real-time data processing: Flink or Spark Streaming are more appropriate.
- For a flexible and scalable solution: Spark offers a wide range of capabilities.
Tips for Successful MapReduce Job Runs
- Optimize Data Locality: Ensure that Map tasks execute on nodes where the input data resides to minimize data transfer.
- Minimize Data Shuffle: Reduce the amount of data shuffled between Map and Reduce phases by optimizing data partitioning and aggregation.
- Handle Failures Gracefully: Implement mechanisms to handle node failures and re-assign tasks to ensure job completion.
- Monitor Job Progress: Track the progress of MapReduce jobs to identify bottlenecks and optimize performance.
- Choose the Right Framework: Select a framework that aligns with the specific requirements of the data processing task.
Conclusion: A Legacy of Innovation and Impact
MapReduce has undeniably revolutionized big data processing, empowering organizations to extract valuable insights from vast datasets. While newer frameworks have emerged to address its limitations, MapReduce’s fundamental principles of parallel execution and fault tolerance remain relevant and influential. Understanding the anatomy of a MapReduce job run provides a foundation for appreciating its power and efficiency, paving the way for effective big data analysis and utilization.






Closure
Thus, we hope this article has provided valuable insights into Deconstructing the Power of MapReduce: A Comprehensive Guide to its Execution. We hope you find this article informative and beneficial. See you in our next article!