Navigating the Landscape of Data Transformation: Map, Use, and Run
Related Articles: Navigating the Landscape of Data Transformation: Map, Use, and Run
Introduction
With enthusiasm, let’s navigate through the intriguing topic related to Navigating the Landscape of Data Transformation: Map, Use, and Run. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
Navigating the Landscape of Data Transformation: Map, Use, and Run
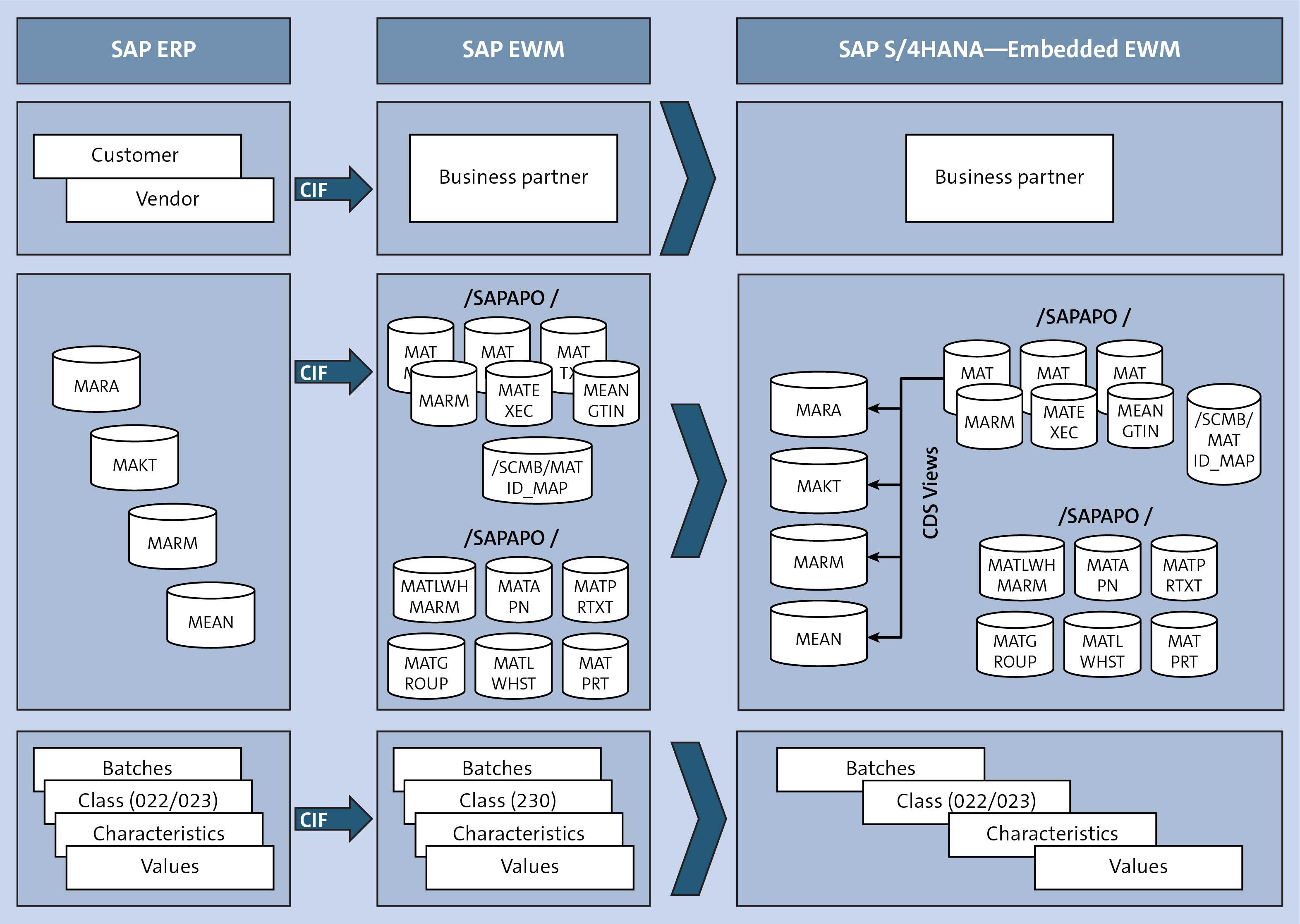
In the realm of data processing and analysis, the concepts of "map," "use," and "run" are fundamental building blocks that enable the transformation and manipulation of data. These terms, though seemingly simple, encapsulate powerful paradigms that underpin the efficiency and effectiveness of data pipelines. Understanding their nuances and applications is crucial for anyone working with data, from data scientists and engineers to business analysts and decision-makers.
Mapping: The Foundation of Data Transformation
"Map" in data processing refers to the process of defining a set of operations or rules that transform data from one format to another. These rules, often expressed in the form of functions or algorithms, specify how each individual data element should be altered or manipulated. This process lays the groundwork for subsequent data operations, ensuring that data is prepared in a suitable format for downstream analysis and processing.
Illustrative Examples of Mapping:
- Data Cleaning: Mapping can be used to remove invalid entries, correct inconsistencies, or replace missing values in a dataset. For instance, a map function might be defined to replace all "NA" values in a column with the average value of the remaining entries.
- Data Conversion: Mapping enables the conversion of data from one format to another. This could involve changing the data type, such as converting strings to numbers, or transforming data units, such as converting temperatures from Celsius to Fahrenheit.
- Data Aggregation: Mapping can be used to aggregate data into meaningful summaries. For example, a map function might be defined to calculate the average sales revenue for each product category in a dataset.
The Power of Use: Applying Transformations to Data
"Use" in data processing refers to the application of a defined mapping to a set of data. This step involves iterating over each data element, applying the defined transformation rules, and generating a new dataset with the transformed data. The "use" phase is where the actual transformation takes place, bringing the defined mappings to life and producing the desired output.
Illustrative Examples of Use:
- Data Validation: After defining a mapping for data validation rules, the "use" step involves applying these rules to the actual data, identifying any inconsistencies or violations.
- Data Enrichment: A mapping for data enrichment might include adding new fields or attributes to a dataset based on external data sources. The "use" step applies this mapping, enriching the original data with the desired information.
- Data Normalization: A mapping for data normalization might be defined to scale or standardize data values within a specific range. The "use" step applies this mapping, ensuring that all data points are comparable across different scales.
Running: Executing the Transformation Pipeline
"Run" in data processing refers to the execution of the entire data transformation pipeline, encompassing both the mapping and use phases. This step involves orchestrating the sequence of operations, ensuring that the defined mappings are applied to the correct data in the right order, and generating the final output.
Illustrative Examples of Run:
- Batch Processing: Running a data transformation pipeline in batch mode involves processing a large amount of data at once, typically on a schedule. This approach is suitable for tasks like data cleaning, aggregation, and reporting.
- Real-Time Processing: Running a data transformation pipeline in real-time involves processing data as it arrives, often used for applications like fraud detection, anomaly detection, and personalized recommendations.
- Interactive Processing: Running a data transformation pipeline interactively allows users to define and execute transformations on demand, providing flexibility and agility in data exploration and analysis.
The Importance of Map, Use, and Run: A Unified Approach to Data Transformation
The concepts of map, use, and run are not isolated entities but rather components of a unified framework for data transformation. By understanding their interconnectedness, we can effectively manage data pipelines, ensuring efficiency, accuracy, and scalability in data processing.
Benefits of a Well-Defined Data Transformation Pipeline:
- Data Consistency and Accuracy: Defining clear mappings and applying them consistently ensures data integrity and reduces errors.
- Scalability and Efficiency: By separating mapping from use, data transformations can be reused across different datasets and scaled to accommodate growing data volumes.
- Maintainability and Reusability: Defining reusable mappings promotes modularity and facilitates maintenance, making it easier to modify or extend data transformation processes.
- Improved Data Quality: By applying appropriate transformations, data quality can be enhanced, leading to more accurate analysis and better decision-making.
Frequently Asked Questions (FAQs) about Map, Use, and Run:
1. What are the different types of mappings that can be used in data transformation?
There are numerous types of mappings, including:
- Value-based mappings: These mappings define specific transformations for individual data values, such as replacing null values with a default value or converting strings to numbers.
- Rule-based mappings: These mappings define rules or conditions that determine how data is transformed, such as applying different transformations based on the value of a specific field.
- Function-based mappings: These mappings use functions or algorithms to perform transformations on data, such as applying mathematical functions or statistical calculations.
- Lookup-based mappings: These mappings use lookup tables to map data values to other values, such as converting product codes to product names.
2. How can I choose the right mapping for my data transformation needs?
The choice of mapping depends on the specific data transformation task and the characteristics of the data. Consider factors such as:
- Data type: The type of data being transformed (e.g., numerical, categorical, text) will influence the appropriate mapping approach.
- Data quality: The quality of the input data (e.g., completeness, consistency) will determine the necessary data cleaning and transformation steps.
- Transformation goal: The desired outcome of the transformation, such as data enrichment, normalization, or aggregation, will guide the choice of mapping.
3. What are the different ways to run a data transformation pipeline?
Data transformation pipelines can be run in various ways, including:
- Batch processing: This approach processes large volumes of data at once, typically on a scheduled basis. It is suitable for tasks like data cleaning, aggregation, and reporting.
- Real-time processing: This approach processes data as it arrives, often used for applications like fraud detection, anomaly detection, and personalized recommendations.
- Interactive processing: This approach allows users to define and execute transformations on demand, providing flexibility and agility in data exploration and analysis.
4. What are some best practices for designing and implementing data transformation pipelines?
Here are some best practices for designing and implementing effective data transformation pipelines:
- Modularize mappings: Break down complex transformations into smaller, reusable components, promoting modularity and maintainability.
- Test thoroughly: Test mappings and pipelines rigorously to ensure accuracy and correctness before deployment.
- Document clearly: Document all mappings, transformations, and pipeline components to facilitate understanding and maintenance.
- Use version control: Track changes to mappings and pipelines to maintain traceability and enable rollbacks.
- Monitor performance: Monitor pipeline execution time, resource utilization, and data quality to identify potential bottlenecks and areas for optimization.
Tips for Effective Data Transformation:
- Start with a clear understanding of the data: Define the source data, its structure, and the desired output format before designing transformations.
- Prioritize data quality: Implement data cleaning and validation steps to ensure data integrity and accuracy.
- Use appropriate tools and technologies: Choose tools and technologies that are suitable for the specific data transformation task and the scale of the data.
- Automate where possible: Automate repetitive tasks to improve efficiency and reduce manual errors.
- Document and test thoroughly: Ensure that all mappings, transformations, and pipelines are well-documented and thoroughly tested.
Conclusion: The Power of Transformation
Map, use, and run are not just abstract concepts but powerful tools that empower us to transform data into actionable insights. By understanding their nuances and applying them effectively, we can unlock the potential of data to drive informed decision-making, optimize processes, and achieve desired outcomes. As the volume and complexity of data continue to grow, the ability to effectively transform data will become increasingly critical, making these fundamental concepts indispensable for anyone working with data in the modern era.
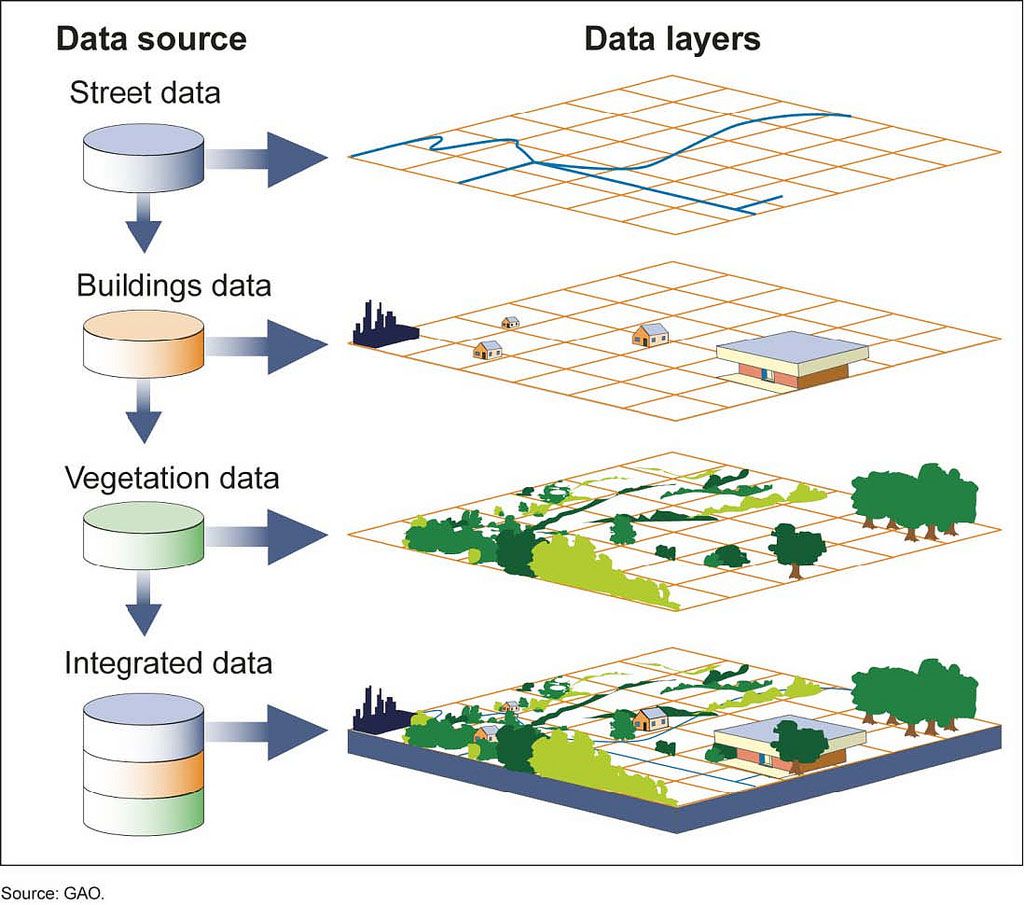



Closure
Thus, we hope this article has provided valuable insights into Navigating the Landscape of Data Transformation: Map, Use, and Run. We appreciate your attention to our article. See you in our next article!